Hi! I am Mayur 👋 Data Professional
Graduated with a MS in Data Engineering & Analytics from Northeastern University (Class of 2024 🎓). With 2+ years of experience in Python, PySpark, SQL, JavaScript and a suite of Cloud services (AWS, GCP, Databricks). My expertise & experience is centered around spearheading Data Engineering | Data Science | Data Analytics projects & pipelines at a petabyte scale, significantly enhancing business operations.
Socials:




About me

Data Science
Data Engineering
Analytics
Cloud Services
Technology & Expertise
Programming Languages
Frameworks & Libraries
Cloud Services & Platforms
Databases
Tools & Other Technologies
Game Development
Work Experience

Data Scientist
CVSHealth
- Augmented P&L forecasting accuracy by 5% using Python & SQL, directly influencing contract adjustments & client outcomes
- Conducted Root Cause Analysis to identify & resolve forecasting errors in rebate rates & specialty cost of goods improving reliability
- Streamlined data pipelines in Databricks with PySpark & MySQL, boosting processing efficiency by 12% & reducing forecast errors
- Integrated artifacts in GCP for Data Forecast Mart, automated ingestion & built APIs, enhancing data availability for underwriters

Data Engineer
Abiomed
- Optimized data pipeline to boost processing speed of Impella pump logs (200+GB/hr) collected from patients across US hospitals
- Collaborated on AWS (Quicksight, Kinesis, Redshift) real-time dashboard on incoming pump data aiding live data analysis
- Executed AWS (S3, Lambda, Kinesis, Redshift) data pipeline plus Python & Kafka for Impella 2.5 pumps clinical metrics (BPM, CO)
- Improved clinical teams data accessibility by building ETL pipeline from shared devices to S3 & Redshift, saving 10 hours weekly
- Revamped ABIs (Virtual Assistant) UI functionality & design for alarm feature using JavaScript & Vue.JS, ensuring quality feedback
- Refined ABIs attribute retrieval accuracy by 7% via PostgreSQL, DBeaver for DBM, Vue.JS (front-end) & Postman for API validation
- Performed in-depth UI testing via Cypress to ensure 100% SRS compliance, significantly improving navigation and layout usability

Data Engineer
Ericsson Global
- Leveraged Python(PySpark, Scikit-learn, Matplotlib, Celery) for data mining & analysis, generating hourly alerts & report for insights
- Crafted & maintained Tableau dashboards, streamlining analysis of 100+ complex MongoDB datasets, reducing analysis time by 8%
- Implemented ETL framework & integrated Kafka streams to optimize telecom data flow from networks, reducing workload by 10%
- Built ETL pipeline to process unstructured data from telecom network APIs on network faults, traffic data & service usage
- Deployed AWS (Lambda, S3, Glue, Redshift) pipeline enriching Tableau dashboards on user data leading to 11% increase in sales
Software Developer
Ericsson Global
- Developed Angular Dashboard using AngularJS & Rest API for a Low-Code Program, augmenting template selection for beginners
- Enhanced the Vila-Portal Project interface with JavaScript, Bootstrap, HTML & CSS, introducing drag-and-drop for analytics
- Achieved 6% increase in analytical insight accuracy by optimizing data visualization using AWS Quicksight on the Vila-Portal Project
- Utilized AWS (S3, EC2, Lambda, & DynamoDB) for backend support, elevating Vila-Portals performance & reliability by 3-4%
Projects
Highlighted below are projects that serve as tangible manifestations of my skills and experience. Each project is succinctly outlined, providing access to code repositories. They collectively underscore my adeptness in resolving intricate challenges, navigating diverse technologies, and proficiently overseeing project lifecycles.
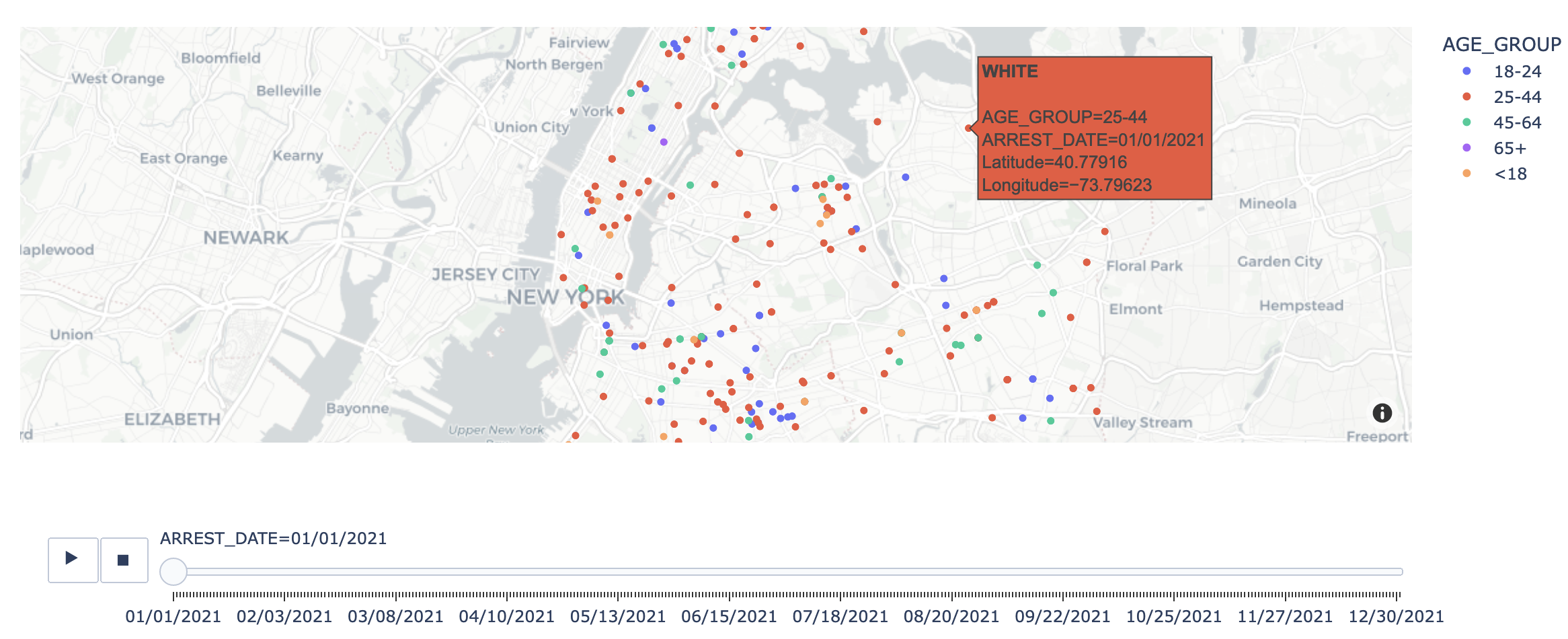

Classification Analysis on NYPD Crime Arrest Data
Presenting an insightful breakdown of NYPD arrests in New York City this year. I conducted comprehensive Data Wrangling, involving meticulous data preprocessing and cleaning. Leveraging Python libraries like Scikit-Learn, NumPy, Pandas, SNS, Seaborn, and Matplotlib, I extracted compelling visualizations. Machine Learning Models --
#DataScience
#KNN
#Linear Regression
#Logistic Regression
#Random Forest
#Naïve-Bayes
#Neural Networks
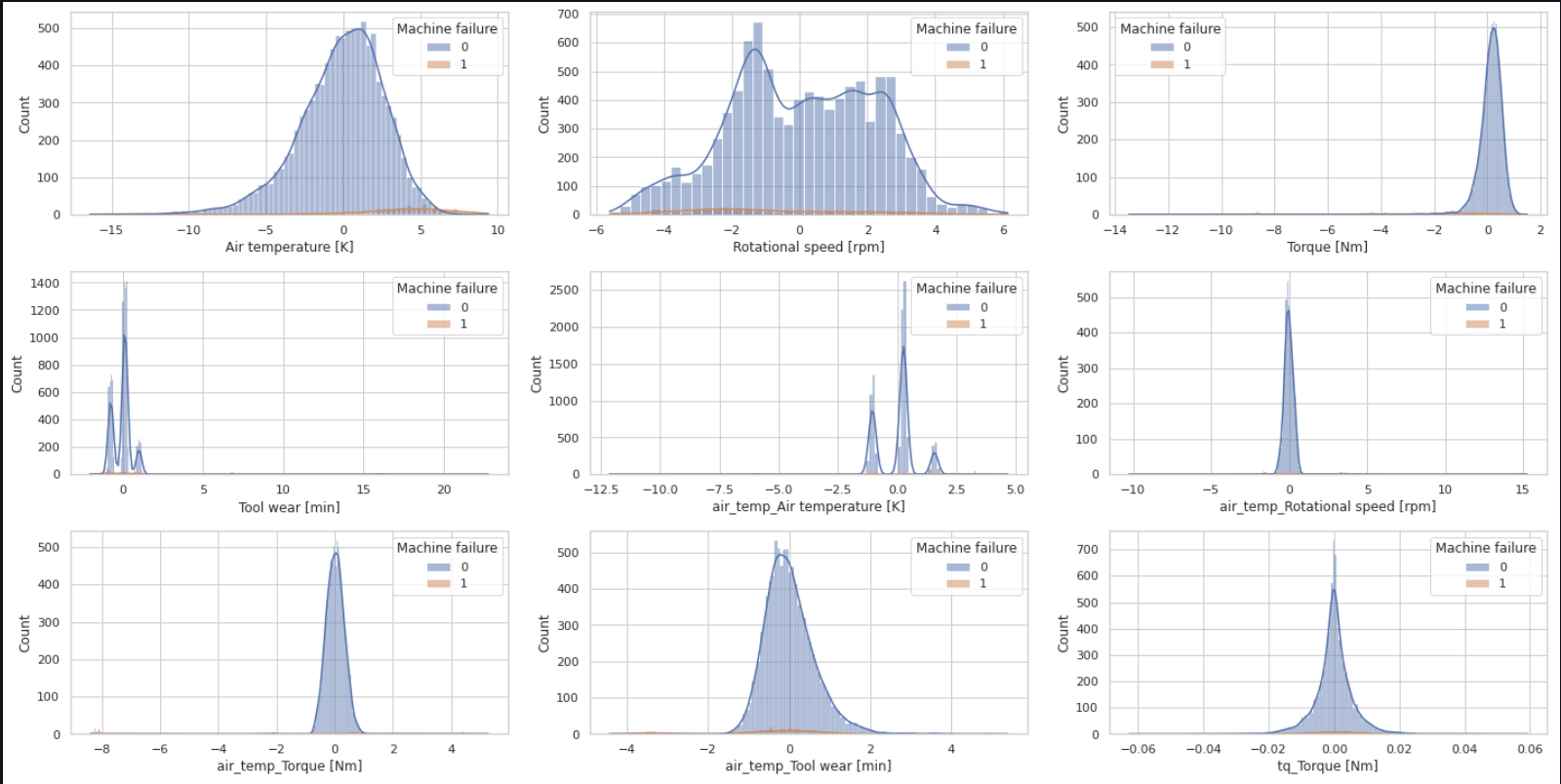
Advanced Machine Learning in Predictive Maintenance
Advanced a predictive maintenance model using machine learning on a UCI dataset with 14 features, like Air Temperature and Torque. Focused on data preprocessing and employed Logistic Regression, Naive Bayes, Decision Trees, and SVMs for predicting equipment failures. Achieved a notable F1-score of 0.95 with Logistic Regression, significantly improving maintenance scheduling and reducing costs
#python
#MachineLearning
#LogisticRegression
#NaiveBayes
#DecisionTrees
#SVM
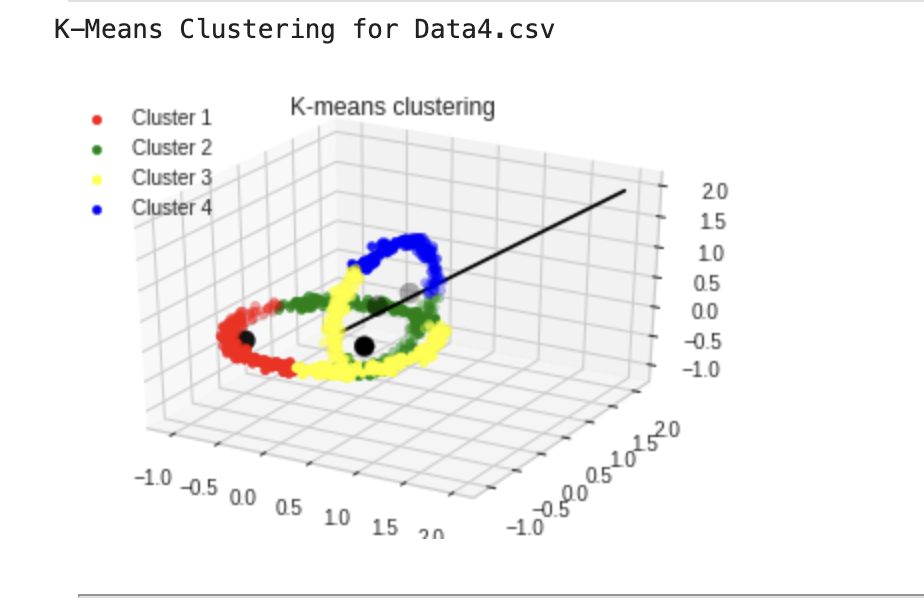
Advanced Data Clustering Techniques in Machine Learning
Implemented K-means clustering and other techniques to segment synthetic and real-world datasets. The project involved thorough data preprocessing and optimization of clustering algorithms, validated through various methods to ensure result accuracy. Demonstrated clustering's potential in uncovering patterns for informed decision-making
#DataScience
#Python
#Sckit-Learn
#Numpy
#Pandas
#Matplotlib
#Seaborn
#KMeans
#AlgorithmOptimization
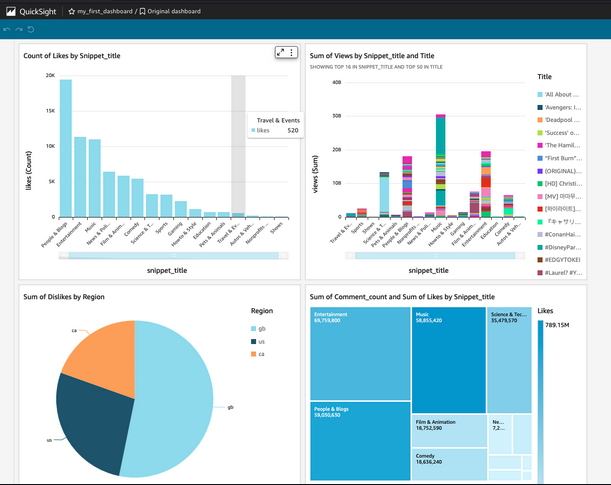
YouTube Data Engineering & Analytics (AWS & PySpark
Developed a data engineering pipeline on AWS for YouTube analytics, encompassing data ingestion, ETL processes with Lambda, and data storage in a scalable S3 data lake. Leveraged AWS Glue and Athena for data organization and querying, culminating in QuickSight dashboards that provided detailed analyses of video trends and viewer engagement
#PySpark
#DataEngineering
#AWS
#Lambda
#QuickSight
#S3
#Athena
#Glue
COVID-19 Data Insights & Trends (AWS & Python)
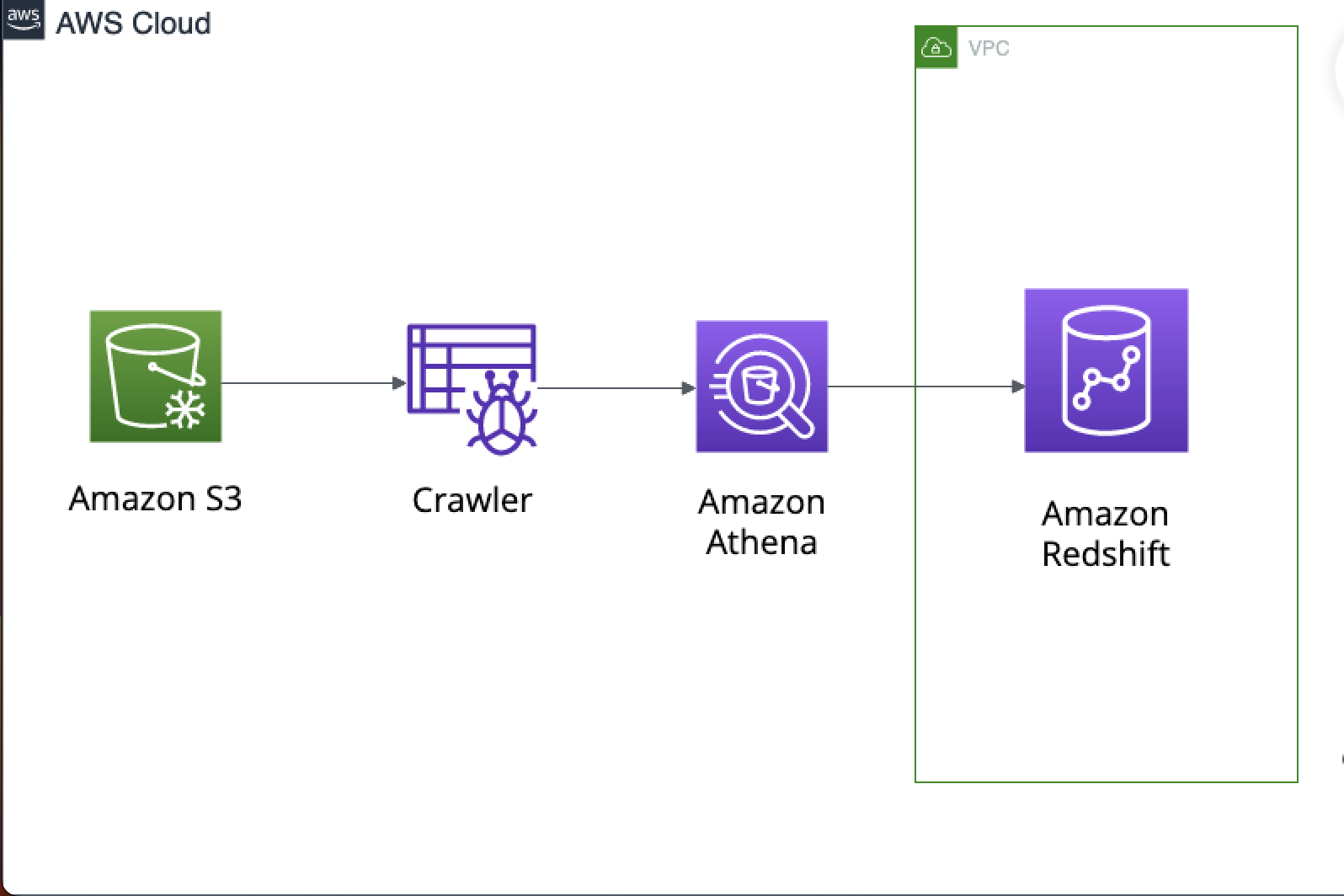
Constructed an AWS-based data analysis pipeline for COVID-19 data, starting with data collection into S3 and utilizing AWS Glue for ETL. A scalable data lake was formed using S3, with Redshift for warehousing and Athena for queries. Advanced data transformations and exploratory analysis were conducted using Python in Jupyter Notebooks, resulting in dynamic dashboards that visualized key pandemic trends and supported public health decisions
#Python
#DataMining
#AWS
#Redshift
#Athena
#Glue
#S3
#Public Health
Spotify Data Engineering and Analysis (AWS & Python)
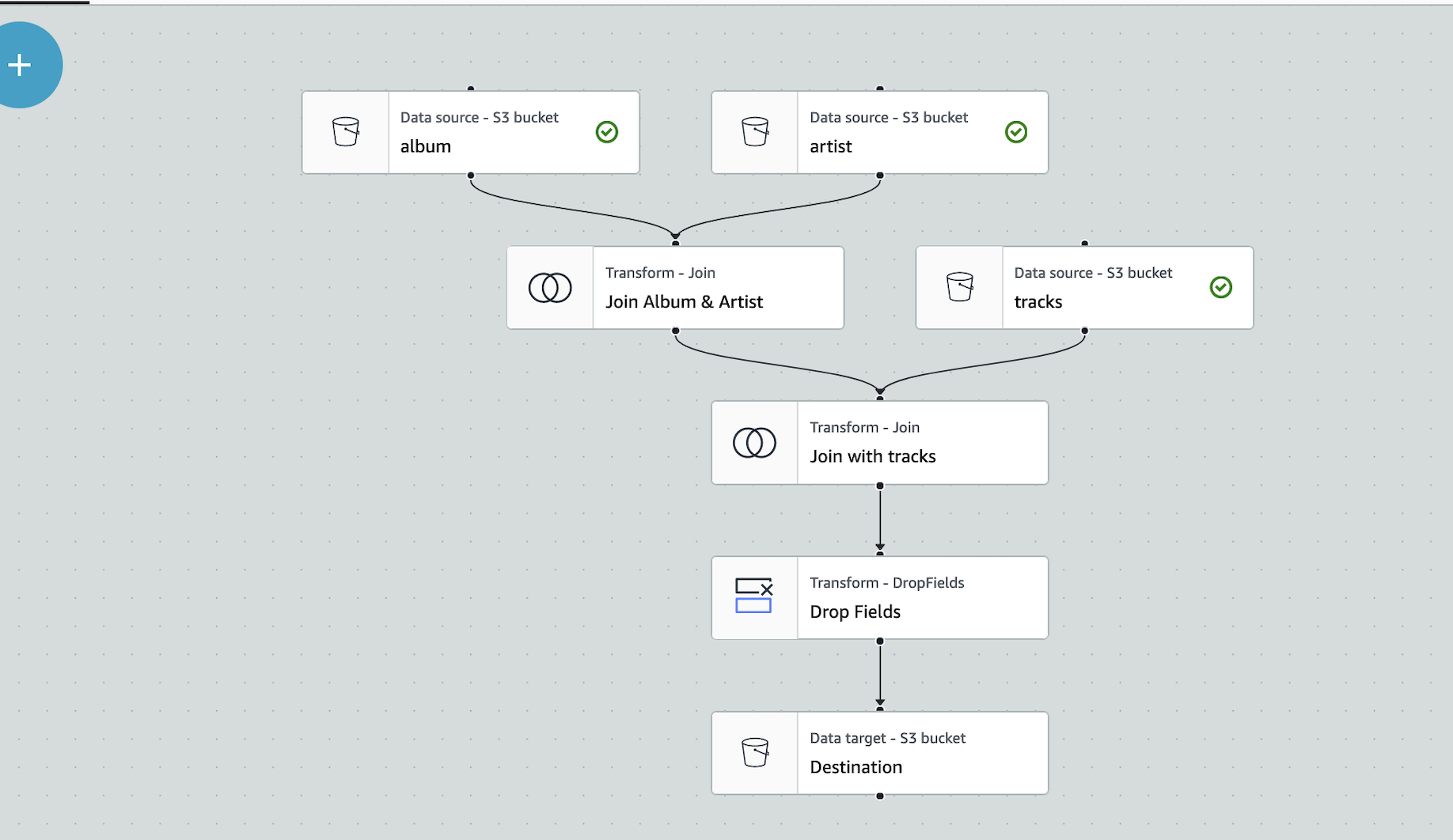
Utilized AWS and Python to analyze the Spotify 2023 dataset, revealing streaming trends. Cleaned and preprocessed data using Python, stored it in S3, and transformed it via AWS Glue for analysis. Leveraged Glue crawlers for schema detection and Athena for SQL querying, which fed into AWS QuickSight dashboards that highlighted music streaming dynamics, providing valuable industry insights
#DataEngineering
#Python
#AWS
#QuickSight
#S3
#Athena
#Glue
#MusicStreaming
Employee Rating Application
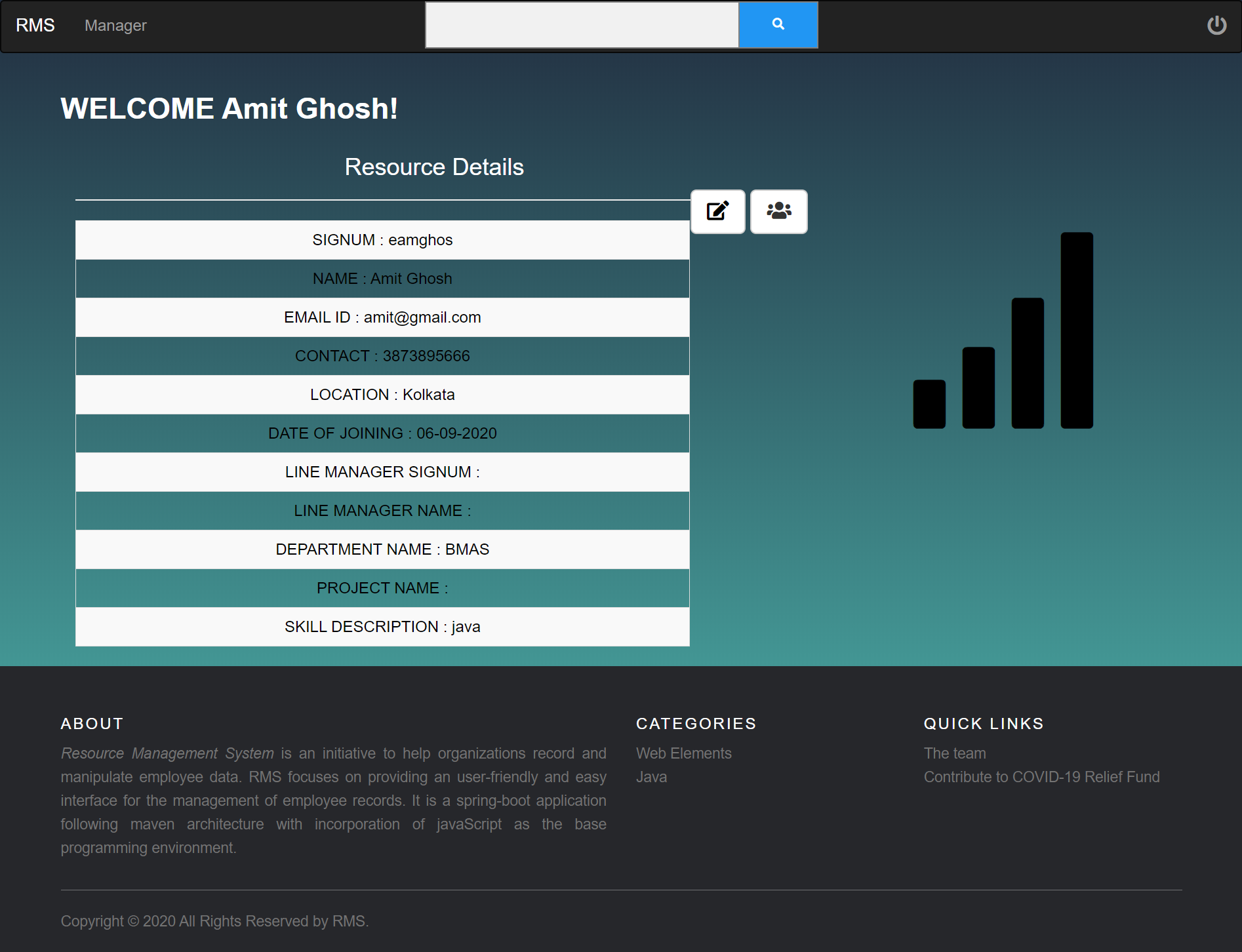
Modelled and developed an employee performance Data Warehouse, by creating a multi-dimensional schema and ran various SQL and NoSQL (MongoDB) queries on it. Visualized and provided some important observations in Python by drawing significant insights on the Review Data.
#Python
#SQL
#MongoDB
#Neo4js
Bike Sharing Analysis in Capital Bikeshare System (Tableau)
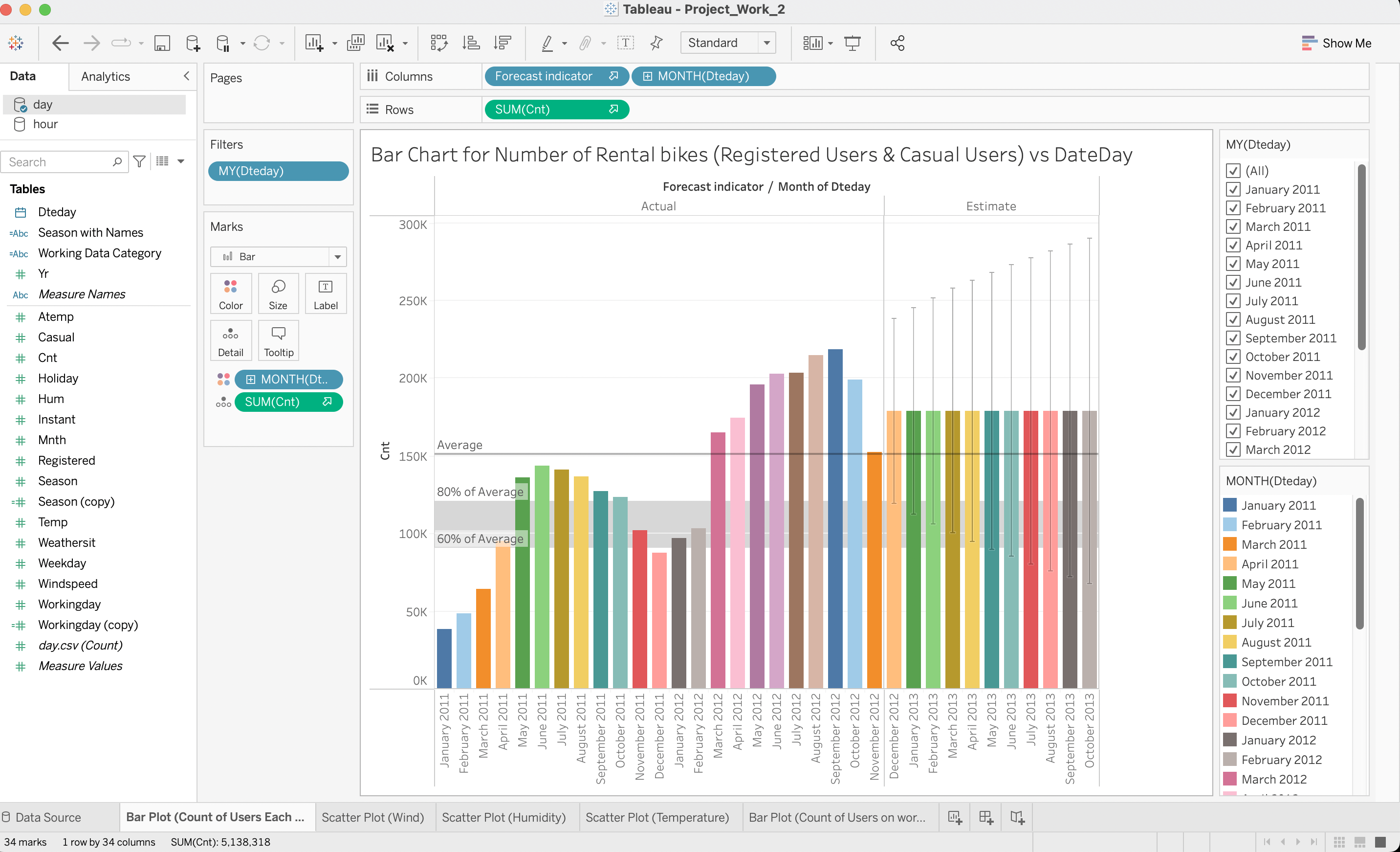
Analyzed Washington D.C.'s Capital Bikeshare data from 2011-2012, studying the influence of weather and seasons on bike-sharing patterns. Processed a dataset of 17,389 records to discover trends in urban mobility, using Tableau to visualize user behaviors, temperature impacts, and rental cycles. Results informed strategic bike distribution to enhance system efficiency and promote sustainable transportation
#DataAnalysis
#Tableau
#BikeSharing
#UrbanMobility
#Sustainability
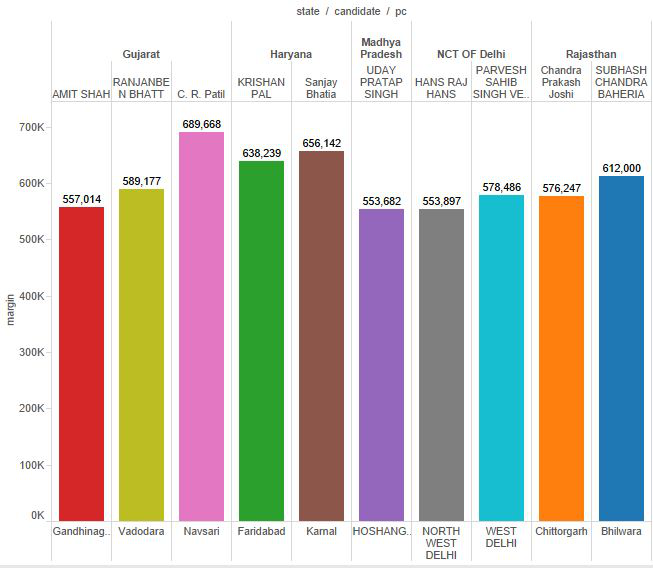
Data Analysis on Elections
This mini project delves into Indian Elections Analysis using Hadoop (Big Data). It encompasses a comprehensive study of the 2019 Indian Elections datasets through Tableau and Hadoop. This endeavor seeks to ascertain political party popularity, decipher intricate trends, and patterns via Python. Additionally, it probes the correlation between party density and topography. The project culminates with a detailed analysis report, utilizing Hive to explore and infer win/loss percentages of parties.
#DataAnalytics
#Tableau
#Hive
#HBase
#HDFS
#MapReduce